Stores
A store tells PriceBuddy how to scrape the price (and other information) from a website. A number of stores are pre-configured, but you can also add your own.
Stores are shared between all users in PriceBuddy, so if you add a store it will be available to all users.
Below will go into more detail on how to add or configure your own stores.
Store name
As you would expect, this is just used for store identification in the UI.
Domains
This is a list of domains that the store is valid for. When you add a product URL, the domain is extracted then PriceBuddy will do a lookup for any stores with a matching domain name. Once a match is found the settings are used to scrape content from that stores product page.
You can add more than one domain to a store, for example, amazon.com and www.amazon.com.
Strategies
These are the rules that PriceBuddy uses to extract the price, title, image and optionally availability from the product page. There is multiple ways to extract these details and you can mix and match different strategies.
Schema.org (JSON-LD)
Probably the most robust way to extract data from a product page, this method reads the JSON-LD data to extract the product detail.
You can read about the spec here. It will only work if the retailer has added the JSON-LD data to the page, but if it does exist, this is the recommended method.
When a store is auto-created, it will test this strategy first.
CSS Selector
This is the most common strategy and is used to extract data. There are plenty of tools and resources to help with this, but the most common way is to use the browser developer tools to inspect the page and find the element you want.
Right click on the data you want to extract and select Inspect from the menu, The developer tools will open and highlight the element in the DOM. Right click on the element and select Copy then Copy selector. You can then paste this into PriceBuddy.
Example for getting the price using CSS Selector
On amazon.com we use developer tools to get the selector span.a-price
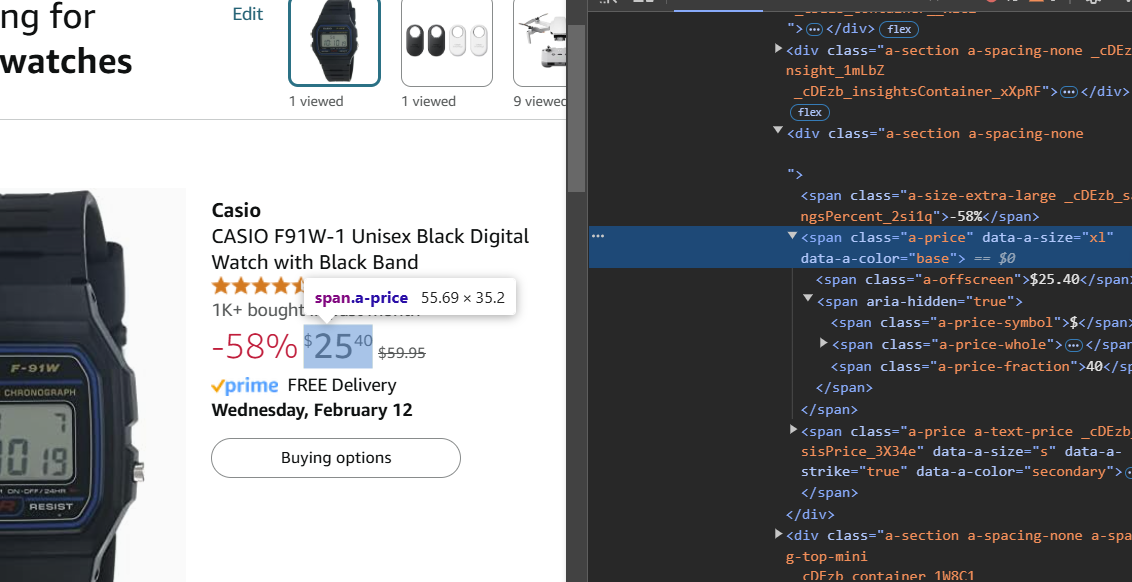
Then in PriceBuddy, we add the selector span.a-price to the price field.
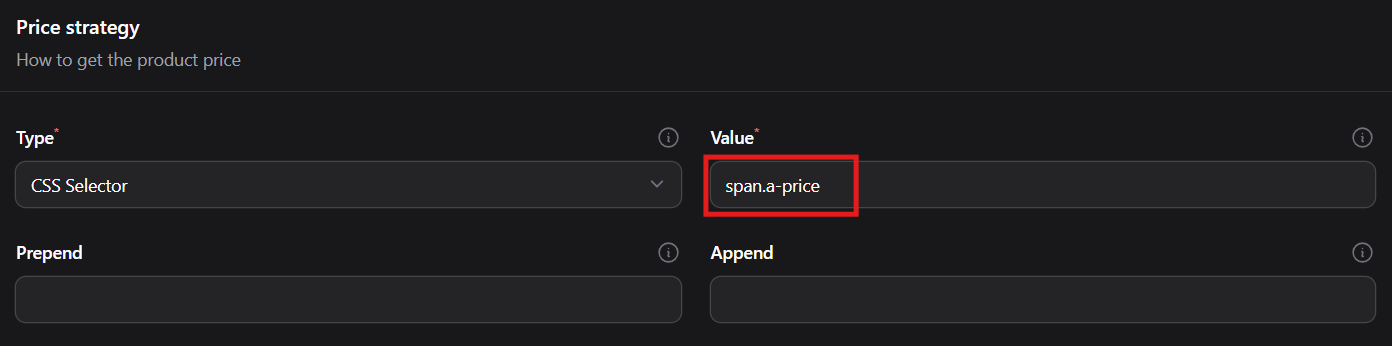
More about CSS Selectors
There is plenty of ways to select elements in CSS, you can use classes (eg .price), ids (eg #price) or even attributes (eg [data-name="price"]). Some Googling will teach you more here, for example this resource.
Getting the value of an attribute
If the data you want to extract is part of an attribute, you can use the | symbol to get the value. For example, if the html looked like this:
<div class="product" data-price="10.00">
You would use the selector .product|price to get the value 10.00.
The most common CSS Selectors for extracting data
- Title -
meta[property=og:title]|content - Price -
meta[property=og:price:amount]|content - Image -
meta[property=og:image]|content
But every site is different.
Availability strategy
Availability is optional, but recommended for stores where products can be pre-order, back order, sold out, or discontinued.
To configure it:
- Add an availability strategy to scrape the availability text from the page
- Add match values to map that scraped text to a status
- Choose a default status when no match is found
This lets PriceBuddy show stock information in the product view and avoid treating unavailable items as normal price matches.
When the availability strategy type is Schema.org, PriceBuddy infers the status directly from the page's schema.org availability value, so you don't need to configure match values for it.
Regex
Regular expressions are a powerful way to extract data from a page. It is more complex to use than CSS selectors but can be more flexible.
Example for getting the price using Regex
If the html contained something like this:
{"price": "10.00", "currency": "USD"}
We could use the regex ~\"price\": \"(.*?)\"~ to extract the price.
Tools for testing Regex
One of the best tools for testing regex is regex101. Paste the "source" of your page into the "Test String" box and your regex into the "Regular Expression" box. You can then see what matches your regex will find.
JSON Path
JSON Path is a way to extract data from a JSON object. This is useful when the data source is an API that returns JSON. The format used is more "dot notation" than JSON path, but it is similar.
Example for getting the price using JSON Path
If your JSON looks like this:
{
"product": {
"title": "Product Name",
"price": 10.00
}
}
You would use the JSON Path product.price to extract the price.
Locale
This is default locale settings for the store, the default can be set in Settings but this will override that for this store.
Locale - This should match the locale/language of the store. Eg. en_US for English (United States) or fr_FR for French. Currency - This should match the currency of the store. Eg. USD for US Dollars or EUR for Euros.
NOTE: Mixing currencies on the same product results in incorrect price comparisons and aggregates.
Cookies
Some stores only show the correct product page or price when a cookie is sent with the request.
You can add cookies to a store so PriceBuddy includes them whenever it scrapes that site. This can help with stores that require a location, age check, login, or other session-based preference before they reveal the real product data.
Scraper service
This is what PriceBuddy uses get the HTML of the product page. There are two services available:
Curl based HTTP request (HTTP)
This is the default and preferred method. It gets the HTML of the page using a basic HTTP request, this is the same as what you would get if you "view source" on a webpage.
It is the fastest and most reliable method, however many modern websites require JavaScript to render the page. This method will not work on those sites.
Browser based request (API)
This method uses a headless browser to render the page and get the HTML. This is means that JavaScript is executed and the page is rendered as if you were viewing it in a browser.
We use SeleniumBase Scrapper to do this, which is a docker image running a headless browser. Internally it uses SeleniumBase.
There are many advanced settings you can use with this service if the site you are scraping is proving difficult to get the data from.
The SeleniumBase Scrapper docker image is interchangeable with Scrapper and was based on the scrapper api.
If you are using Scrapper, it provides its own web interface for testing and debugging, if you're using the default docker-compose.yml you can access this at http://localhost:3000.
Auto store creation
PriceBuddy can auto create stores for you given only the product URL. This works by attempting to scrape the page and extract the price via common strategies. After a successful strategy is found the store will be created.
This will not work with all stores, but it does work for most. It will only use the Curl based HTTP request to get the page contents for performance reasons.
If auto creation fails, try manually creating the store and using the API scraper or more custom strategies.
Testing a store
When editing a store, use Test to try a product URL and see exactly what the current strategies extract. Results are shown in a comparison table (title, price, image, availability and more) so you can confirm each field before saving. You can switch the scraper service and re-test, and — if an AI provider is configured — use Compare with AI to see what AI extracts from the same page alongside the scraped values.
AI price extraction
If an AI provider is configured, you can enable AI price extraction per store. When a normal scrape finds no price, AI reads the page and tries to recover one.
It is purely additive: it only fills a genuine gap, never overrides a scraped price, skips items detected as out of stock, and only accepts a confident result. You can optionally choose a specific provider for the store.
AI self-healing
When a store's strategies stop working (for example the site changes its markup), AI self-healing can propose fresh selectors to repair the store config — and can even bootstrap a new store from just a product URL. PriceBuddy tries deterministic heuristics first and only escalates to the AI provider when needed.
From the store test view you can run Heal with AI to preview a proposed fix and apply or discard it; nothing is saved until you choose to. Self-healing can be turned off per store with Disable AI self-healing for this store.
Requires an AI provider with the Healing feature enabled.
Sharing a store
If you create a store and want to share it with others, you can export the store as JSON by clicking the "Share" button. You can then give this JSON to others and they can import it into their PriceBuddy instance.